



JS处理深层遍历 系统栈递归和while的区别
更新时间: 2022-09-09 15:50:49
点击量: 1475
标签: 算法
简介: 本篇简单测试一下递归和while的区别, 在处理一些计算问题时使用的最多的两种运算方式
文章均为个人原创, 搬运请附上原文地址感谢, 原文来自MasterYi博客
前言
- 本篇简单测试一下递归和while的区别, 在处理一些计算问题时使用的最多的两种运算方式
执行性能 & 内存开销
- 这里不模拟业务逻辑了, 就每次生成一个标准的数组 [{k: '测试', v: 1}, {k: '测试', v: 2}, {k: '测试', v: 3}, {k: '测试', v: 4}]
- 然后我们通过 100、1000、1W、10W 等运算次数来看一下开销和时长
- 测试环境 nodeJs v16.17.0 、cpu i7-9700 、内存 32G
- 每次执行3次取平均值
执行100 次
| 方法 | 执行时长 | 堆内存 | 总内存 |
|---|---|---|---|
| 递归 | 0.20ms | 4.76M | 29.03M |
| while | 0.16ms | 4.76M | 29.00M |
执行1000 次
| 方法 | 执行时长 | 堆内存 | 总内存 |
|---|---|---|---|
| 递归 | 1.31ms | 4.76M | 29.26M |
| while | 0.42ms | 4.76M | 29.26M |
执行1w 次
| 方法 | 执行时长 | 堆内存 | 总内存 |
|---|---|---|---|
| 递归 | 21.73ms | 9.01M | 33.38M |
| while | 3.65ms | 6.26M | 30.75M |
执行10w 次
- 递归过深导致堆栈溢出, 无测试结果 RangeError: Maximum call stack size exceeded
| 方法 | 执行时长 | 堆内存 | 总内存 |
|---|---|---|---|
| while | 9.15ms | 6.26M | 30.86M |
测试总结
- 首先语言都会有函数的执行栈管理、我这里拿js举例执行AO
- 递归的堆栈释放得等到函数探底、再由底部开始一层层执行结束后释放内存, 虽然JS没有明确调用栈深度, 但层级过深的递归很容易导致堆栈溢出程序宕机
- 上方代码没得业务逻辑,在参加运算逻辑处理(多申请点变量空间后)后对性能开销的情况会更加显著递增
各自的特点
函数递归
- 相信我们大多在学校里学的时候听得最多的对于递归的解释就是(函数体内包含函数本身)
- 其实递归就是把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,编写少量的程序就可描述出解题过程所需要的多次重复计算
- 递归需要有边界条件、递归前进段和递归返回段
- 函数递归走的是JS的系统执行栈, 释放得等到函数探底, 返回的过程中才开始释放
示例
- 假设处理一个比较经典的阶乘问题
function f(n){
if(n === 1){
return n;
}
return n * f(n - 1)
}
f(5); // 120- 可以自行使用谷歌调试(断点查看执行栈、我这里直接放截图了)
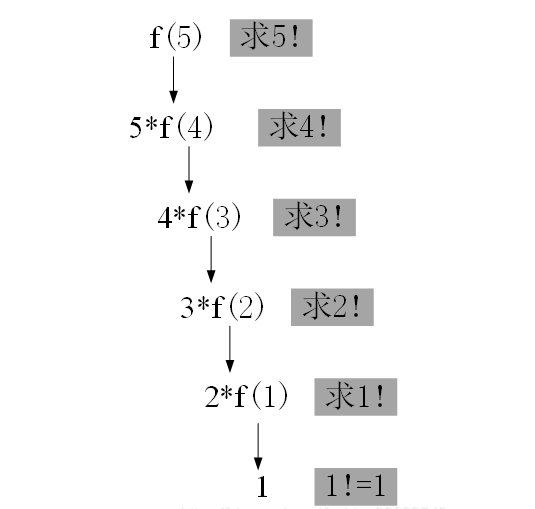
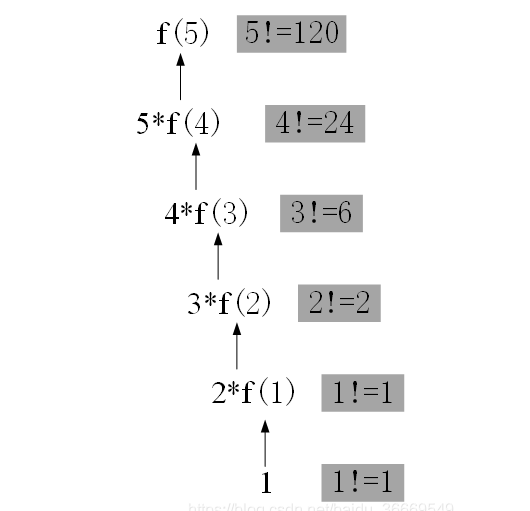
- 可以看到探底到n=1的时候执行栈内有 5个f() , 探底后返回再一层层的从内释放 n=2时释放 f(1) , n=3时释放f(2)依次类推完成了递归
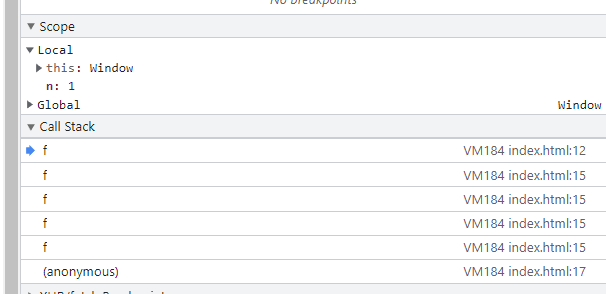
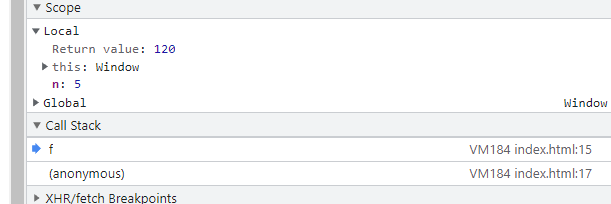
- 执行图解 (等探底 f(1)的时候才开始执行返回, 回收顺序为 f(1) -> f(2) 依次类推 f(5) 最后被抛出), 栈的先入后出
while
- while是计算机的一种基本循环模式 【 while(表达式){循环体} 】, 循环体执行结束后会再次进入表达式判断是否需要再次执行
- 因为while没有入栈暂存变量的必要, 所以每次循环改变的变量的值都是同一地址空间的值, 所以也不会因为深度问题产生内存积压, 开销就比较小
共性&区别
共性
- 循环式地处理相同的某一大块语句,每次循环的运算操作和顺序完全相同
区别
- 递归,就是函数调用,有入栈,必有出栈,入栈的好处是把变量暂存起来,出指针传值方式外的变量, 每次循环处理的变量都是当前的栈空间的变量, 这样就不用考虑会影响上一层的变量的值、但这样会有缺点就是容易堆栈溢出, 内存积压过大
- while 就是在一个空间进行重复操作, 只有一个执行AO, 不会自动存储上一次执行的结果集, 没有入栈, 也不需出栈
- 白话文比喻一下用while 和 函数写递归的区别, 假设拿绳子围着一棵树转圈, 函数递归就是围着树转圈但会因为深度而不断的延长绳子直到主动停止或者绳子长度不够而结束, 而while就是拿着和绕树一圈长度的绳子一直转圈圈直到停止
- 两种方式各有各的特点、了解后按需使用即可
如何使用while深层遍历
- 使用深层遍历的场景, 例如阶乘,树都是需要上一次的结果集来进行下一步的操作, 自己和自己建立关系
- 但是while并没有系统的出入栈管理每一次的值, 所以我们在使用while来写深层遍历时便要模拟好出入栈的场景
示例一 阶乘
- 当然这个例子比较简单还没涉及到出入栈
let n = 5;
let num = 1; // 需要一个上层变量来存储上一次的变化
while (n > 1){
num = num * n;
n--;
}
console.log(num); // 120示例二 树查询
- 这里假设要在某一个文件夹中查询我们想要的文件
- 看到这里大家可以试着用递归的方式去试着实现, 自己动手过后就很容易看懂下方的模拟了,函数方式就不写了, 学了的得用了才知, 光看是不会理解的
// 首先模拟一个文件夹, 假设携带 children 为文件夹, 没有的就是文件
let folder = [
{
name: '学习资料',
children: [
{ name: 'TCP协议' },
{ name: '页面重绘问题' },
{ name: '资源竞态锁' },
{
name: 'CSS资料' ,
children: [
{ name: 'CSS弹性布局' },
{ name: 'CSS过渡动画' },
{ name: 'CSS伪类' }
]
}
]
},
{
name: '我的游戏',
children: [
{ name: 'LOL' },
{ name: 'DNF' },
{ name: 'QQ飞车' }
]
}
]
function search(name){
let stack = []; // 模拟执行栈
let result = []; // 用于存贮结果集
stack.push(...JSON.parse(JSON.stringify(folder))); // 模拟启动条件, 入栈要查询数组
while (stack.length) { // 只要栈内还有东西便继续执行
let item = stack.pop(); // 出栈执行
if(item.children){
stack.push(...item.children); // 判断为文件夹则继续入栈进行子集查找
}else{
if(item.name.indexOf(name) > -1) result.push(item);
}
}
return result;
}
console.log(search('LOL')); // [ { name: 'LOL' } ]
console.log(search('CSS')); // [ { name: 'CSS伪类' }, { name: 'CSS过渡动画' }, { name: 'CSS弹性布局' } ]